 成为VIP
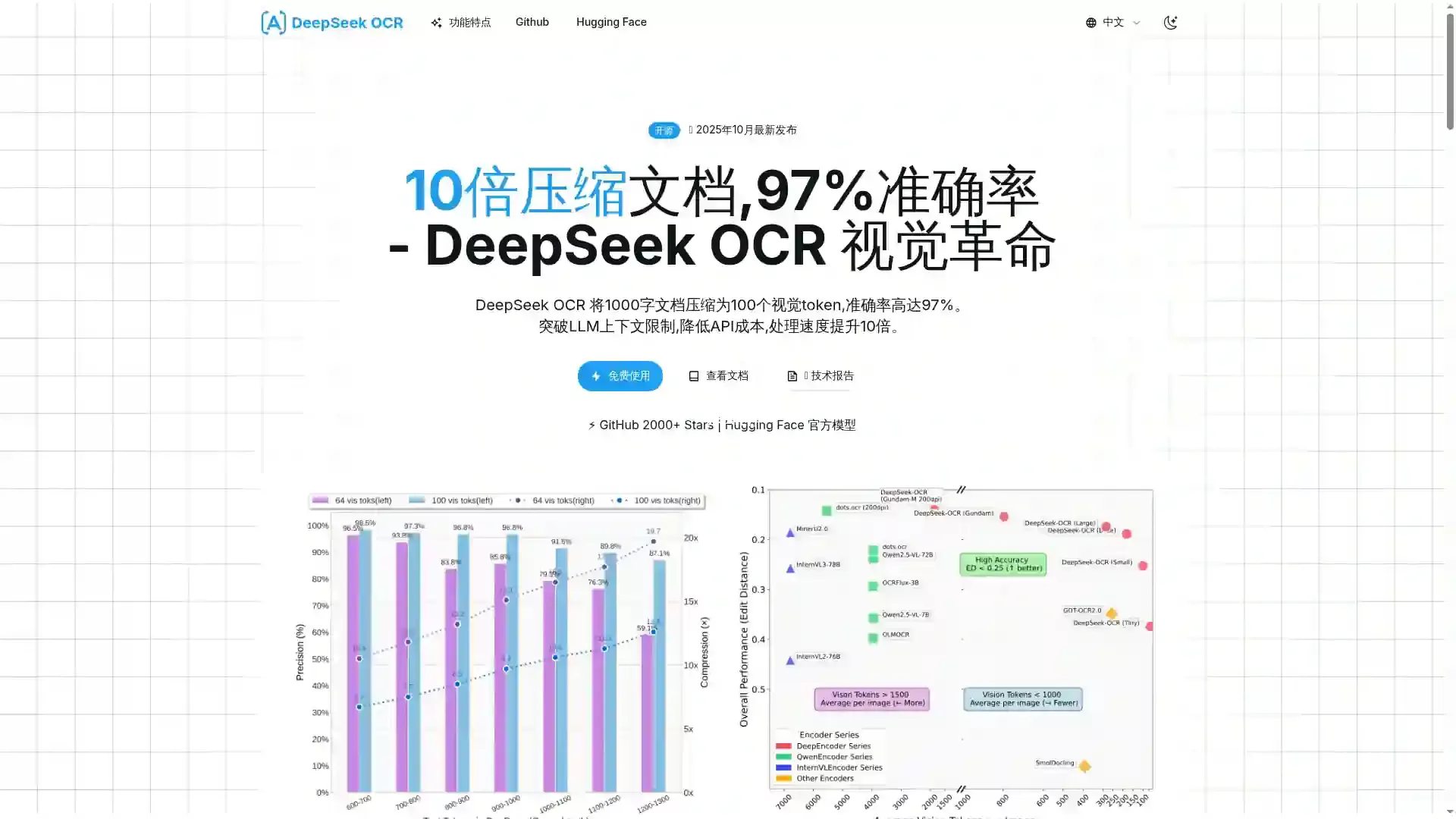
成为VIP一款开源视觉文本压缩模型,旨在将文档转换为高度压缩的视觉token,压缩比可达7-20倍,同时保持高达97%的准确率。
不仅突破了传统OCR的局限,还降低了API成本,适用于多种文档类型和语言,支持快速预览和详细提取等多种应用场景。
DeepSeek OCR 支持约100种语言,包括中英日韩等多语言混合文本。可以处理的内容类型包括:纯文本、数学公式(LaTeX)、表格、图表、化学方程式、几何图形等。特别适合处理学术论文、技术文档、多语言商务合同等复杂文档。
核心功能:
视觉Token压缩
独创的视觉压缩技术,将文档转换为高密度视觉token,压缩比达7-20倍。
多模态识别
支持文本、数学公式(LaTeX)、表格、图表、化学方程式等多种内容类型。
多语言支持
支持约100种语言,包括中英日韩混合文本,无需手动切换语言。
灵活分辨率
提供4种分辨率模式(64-400 tokens),从快速预览到精细提取自由切换。
开源免费
完全开源,可商用,提供 GitHub 仓库和 Hugging Face 模型下载。
高性能处理
单A100 GPU每天处理20万页,20服务器集群达3300万页/天的超强性能。
在线网址:https://deepseekocr.site/zh
声明:本站内容均收集于互联网,如不慎侵犯到您的版权利益,请附带相关证明文件来信本站将立即予以下架删除。
评论(0)